

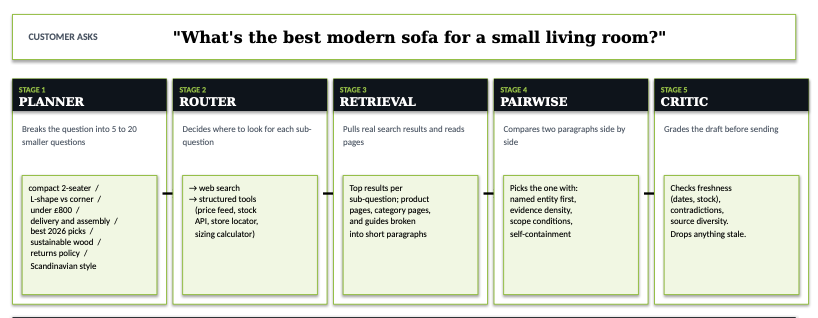
The 5 stages of agentic RAGs
Pages don’t compete in AI search. Paragraphs do.

A client of ours ranks #1 organic for a particular search term I can’t disclose here. Bofu keyword. Good page. Good rankings. Their team would tell you, fairly, that there is nothing to fix.
Then we ran the page through a five-stage agentic RAG framework that Mike King at iPullRank made accessible last week with his Beyond RAG piece (thanks Mike!). The audit does not measure rankings. It measures whether your paragraphs would survive the set of decisions AI search systems now run between a customer’s question and the answer they output.
Our client lost the pairwise on that pricing sub-query to three competitors who ranked below them. All three would beat our client inside ChatGPT, Gemini, Perplexity, and Google AI Mode for that exact question. Why. Because all three open their pages with a number. Our client’s page does not show a price anywhere.
What actually changed
Old SEO assumed one moment of truth. The SERP. You ranked or you did not. You got the click or you did not.
AI search runs five moments of truth before the customer sees a sentence. The assistant takes one question, breaks it into five to twenty smaller questions, picks a tool for each one (web search, structured data, calculator, maps), pulls top results, chunks each page into short paragraphs, runs a tournament between paragraphs from competing sources, and then grades the surviving draft for freshness, contradictions, and source diversity. Anything that fails any gate gets cut.
The paragraph is the unit of competition now. Not the page.
What we built
Mike’s article describes the process. We took the architecture and built an internal replica of sorts so we better see where a client’s content drops out. Same five stages: Planner, router, retrieval, pairwise reranker, critic. We feed it a target URL and a priority query. It runs the loop on real SERP data. It writes a trace showing the journey for that URL across every sub-question the planner generated. Where it surfaced. Where it made the pool. Where it won pairwise. Where it passed the critic. Where it ended up cited.
The trace becomes a sheet. Tab one is the report. Tab two has one row per losing pairwise verdict with the original passage, a rewrite, and a written explanation of which judging criterion the rewrite satisfies.
Two runs, one client
We ran it twice for the same brand.
Run one was their head term against the homepage. The target surfaced in 14 of 20 sub-questions. It won the pairwise on 5 of them. Every one of those wins came from a passage that named the brand’s unique accreditation in the first sentence. The losses had the opposite shape. The competitor’s first sentence named an age, a number, or a price. Our client’s first sentence said things like “Choose your … mode” or “Enrol today.”
Run two was a different priority query against a product page. The target surfaced in 9 of 20 sub-questions. The interesting finding came from three sub-queries where a different page on the same domain ranked instead of the strategic page. A blog post ranked for the head definitional query. An activities page ranked for the project-ideas query. A safety guide ranked for the safety query. The brand was visible across the topic. The strategic page was not. Internal linking from the blog ecosystem into the course page would close that gap in days.
The pattern behind the losses
Almost every pairwise loss flips on a 90-minute copy edit.
In this example: Lead with the named entity. Put the number the system obviously wants, a price, or a quantified scope condition in the first 15 words. Make the paragraph self-contained, so it reads as a complete answer even if you copy it out and paste it into a blank doc. Add a “Last updated” line. The reranker is not subtle. The criteria are public, repeatable, and predictable.
The bigger change is mental, not technical. Stop optimizing pages. Start optimizing the heading + first sentence under every heading. Pages do not compete in AI search. Paragraphs do.
The honest caveat
We cannot see inside Google’s planner, ChatGPT’s reranker, or Perplexity’s critic. Mike is direct about this in the piece, and his solution makes sense. Build your own observable copy of the loop and calibrate it against the visible parts of production systems like Deep Research. That is what our harness does. It is a proxy, not a replica. But a proxy you can read beats a black box you cannot.
The retrieval-once playbook is over. Five gates per question is the new default. If your team is still arguing about position tracking, they are measuring the wrong thing.
Mike King’s Beyond RAG is worth your hour if you make a living from organic search and more and more from your brand’s visibility in AI.